Prædiktivt vedligehold lover positivt i forhold til at kunne spare virksomheder for unødvendige udgifter ved at optimere vedligeholdsstrategien, og tilgangen anvendes i flere virksomheder.
Af Søren Egedorf, Teknologisk Institut
Prædiktivt vedligehold, Predictive Maintenance (eng.), er et værktøj, der kan anvendes bredt på mange systemer. Formålet er at sætte ind med vedligehold på et teknisk system, når der er behov for det - i modsætning til at vedligeholde med regelmæssige intervaller.
Ved at overvåge systemet vha. sensorer og identificere nogle mønstre i sensordata, der kan indikere fremtidige fejl, sænkes en række omkostninger. Man undgår derved at vedligeholde, når det godt kunne vente, og ligeså vedligeholder man hyppigere, når det er nødvendigt. Sensordata kan komme i mange former – f.eks. vibrationssignaler, temperatur, tryk, flow, m.m. og det kan være udfordrende at anvende disse sensordata til prognoser.
Til behandling af disse data kan det således være relevant med nogle mere avancerede databehandlingsmetoder. Indenfor kunstig intelligens (AI) vil vi i denne artikel vise potentialet af to metoder til prædiktivt vedligehold. Vi anvender og evaluerer metoderne på to forskellige datasæt: Et simuleret datasæt over flyturbiner og et virkeligt datasæt over kuglelejer. For at få et mål for hvornår vedligehold kræves, anvendes det engelske begreb Remaining Useful Life (RUL) – restlevetiden. Til at bestemme RUL for systemet anvendes i begge metoder run-to-failure (RTF) data. Dette er historiske sensordata, der har været opsamlet op til fejl i systemet. Metoderne skal bruge viden fra disse data til løbende at forudsige RUL på realtidsdata.
To metoder til prædiktivt vedligehold
Canonical Variate Analysis (CVA) med fuzzy logic tilgang:
CVA er en såkaldt dimensionsreducerende metode. Hver sensor der måler på systemet, udgør en ekstra dimension, og har man mange, kan man hurtigt få svært ved at få overblik over systemets tilstand. Derfor kan CVA med fordel anvendes, da den så at sige ”sammenpresser” data i kun en enkelt dimension, der vil være nem at overskue på en enkelt graf. Ud over bedre overblik skaber metoden nogle andre fordele som f.eks. at den er ekstra følsom, samt at den er god til at skelne, om ændringer i data skyldes, at en fejl er ved at udvikles, eller om vi blot er i en anden driftstilstand. Den er altså robust. Uden at gå i detaljer, da denne metode er mere avanceret, kan nævnes, at outputtet fra metoden er denne enkelte tilstandsindikator, der som nævnt, er en ”sammenpresning” af data.
Ved at have historiske RTF-data med tilstandsindikatorer kan man heri ud fra realtidstilstandsindikatoren lede efter lignende mønstre vha. en fuzzy logic-tilgang. Man leder altså efter ligheder mellem den monitorerede tilstandsindikator og de historiske tilstandsindikatorer, og idet det er historisk data, kender vi restlevetiderne i de fundne lighedspunkter. Herudfra kan vi estimere RUL for det monitorerede system i realtid.
Long Short-Term Memory (LSTM) neuralt netværk:
Netværket der anvendes, er fra en open-source GitHub Python-tekstfil. Kunstige neurale netværk er bygget op af forskellige lag af neuroner. Der er et input-lag og skjulte lag, og der er et output. I neuronerne multipliceres inputtet til et neuron med en vægt. Hernæst går informationen igennem en aktiveringsfunktion, der skaber outputtet fra neuronet til næste neuron. Under træningen af netværket haves et træningsdatasæt med sensordata samt korrekte restlevetider (RTF-data). Den information bruger netværket til at lære de vægte, der ved at køre data gennem hele netværket minimerer den såkaldte tabsfunktion. Denne bestemmer ud fra en given funktion forskellen i den forudsagte RUL og den faktiske RUL. Er forskellen ikke acceptabel opdateres vægtene vha. en optimeringsalgoritme, så netværket bliver bedre til at forudsige korrekt RUL næste gang, den ser træningsdatasættet. Når træningen er overstået, kan netværket forudsige RUL på realtidsdata.
LSTM er en type neuralt netværk, der er god til tidsseriedata. Detaljerne er ude af sigte med denne artikel, da opbygningen af denne type netværk er væsentligt mere avanceret end standard neurale netværk. Men det trænes på samme måde som ovenfor beskrevet og er også opbygget i lag og neuroner.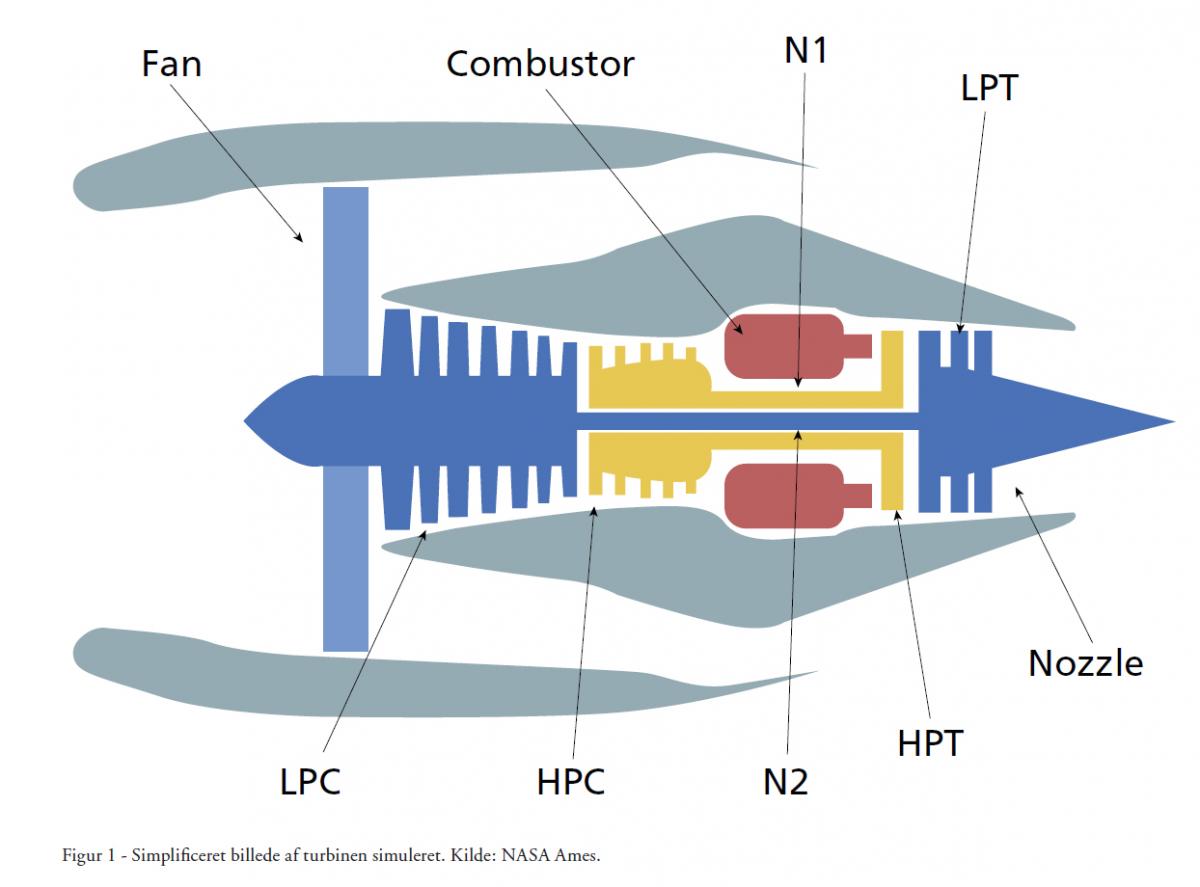
Forklaring af turbinedata og resultater
Figur 1 viser et simplificeret billede af turbinen der simuleres. Datasættet består af fire under-datasæt med stigende sværhedsgrad. Simuleringen skabte RTF data og testdata af 21 sensorer for flåder af turbiner i de fire under-datasæt. Det første indeholder sensordata fra 100 RTF-turbiner samt 100 testturbiner, vi gerne vil bestemme restlevetiden for (vores realtidsdata). Dette datasæt indeholder kun en enkelt driftstilstand og fejltilstand. De resterende tre datasæt indeholder flere RTF-data, men er samtidigt også af højere sværhedsgrad pga. flere driftstilstande og/eller fejltilstande. Hver turbine er af samme type, men starter med forskellige grader af begyndelsesslid og forskellig produktions-/fremstillingsvariation, som er ukendt for brugeren af datasættet. Med andre ord ved vi ingenting om, hvor langt den givne turbine er nået i sin livscyklus ved databegyndelsestidspunktet. Testdata er de data, hvor vi gerne vil bestemme restlevetiden og for at kunne vide, hvordan metoden på datasættet præsterer, har man faktiske restlevetider for testdatasættene.
Potentialet ved de to metoder
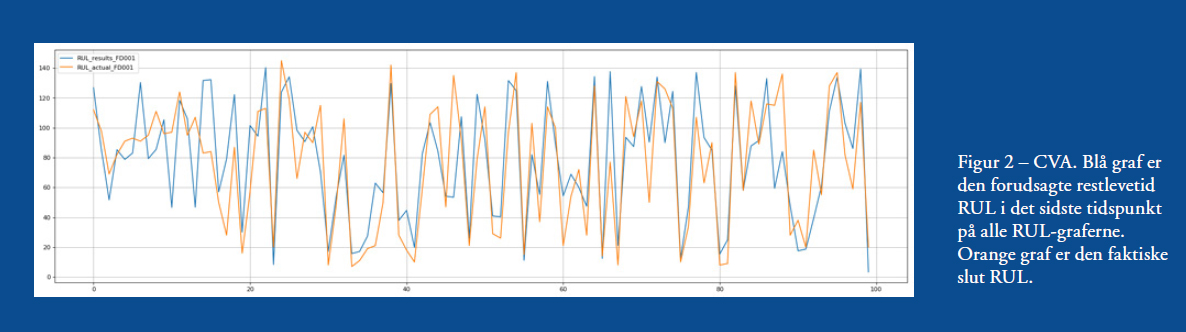
Ved bestemte tilgange kan man bestemme de såkaldte hyperparametre for CVA-metoden og fuzzy logic-tilgangen. De skal forstås som parametre, der får metoden til at ”passe” til det givne datasæt. Når disse er bestemt, kan man anvende algoritmen på data: Nævnte CVA anvendes på sensordata fra hver RTF-turbine for at skabe tilstandsindikatorer, og CVA og fuzzy logic-tilgangen anvendes på data fra hver test-turbine til at skabe grafer over restlevetider (RUL-grafer). For det første datasæt kan resultatet ses i Figur 2. Figuren viser den sidste estimerede RUL-værdi fra hver af de 100 RUL-grafer fra testturbinerne (blå graf) samt den faktiske RUL for turbinerne (orange graf). Som eksempel på hvordan en enkelt RUL graf ser ud, kan nævnes den for turbine 93; se Figur 3.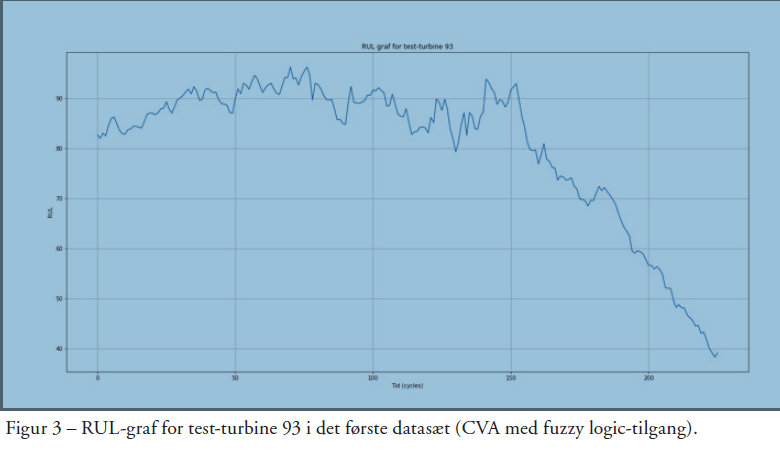
Det er det sidste punkt på denne graf, der er plottet i Figur 2 sammen med tilsvarende slut RUL for resten af testturbinerne. Det vil også være den RUL-graf, man tager beslutninger ud fra i en anvendelse, og som det ses, er RUL lidt under 40 i slutningen, så man kan godt vente med vedligehold i noget tid endnu. For at sammenligne LSTM-metoden med den CVA-baserede metode kan tilsvarende figur ses i Figur 4.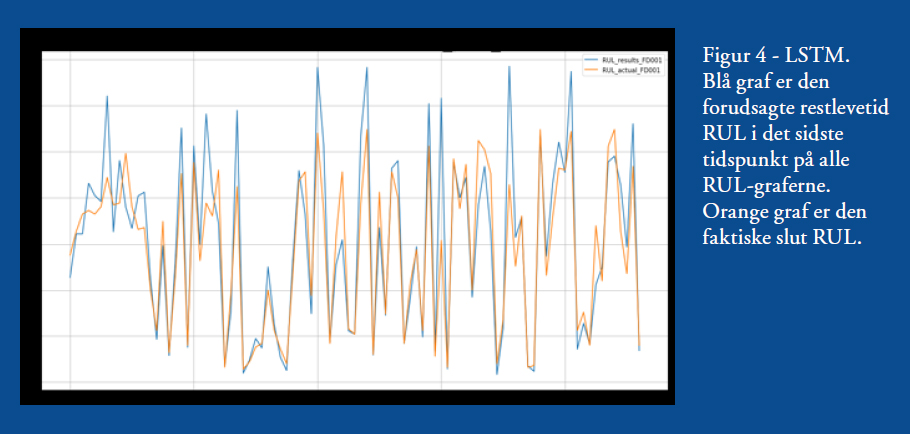
Umiddelbart visuelt vurderet klarer det neurale netværk sig bedre end CVA-metoden, da der er bedre sammenfald mellem den forudsagte og faktiske slut RUL. Pga. omfanget af denne artikel vises ikke resultater på alle fire datasæt, men lignende tendenser gør sig gældende; LSTM-metoden klare sig altså bedst og CVA-metoden har udfordringer på nogle af de sværere datasæt.

Forklaring af kuglelejedata og resultater
Dette datasæt er et virkeligt datasæt, hvor man har udført fysiske eksperimenter for at skabe det. Forsøgsopstillingen kaldes PRONOSTIA og kan ses på Figur 5, og opstillingen er bygget til at kunne accelerere degenerationen af kuglelejer ved at udsætte dem for stress. Man har to accelerometre, som måler vibrationer på kuglelejet under et eksperiment. Der er blevet lavet eksperimenter på 17 kuglelejer, og man har under alle 17 eksperimenter optaget vibrationsmålinger, indtil lejet fejler (vibrationerne overstiger 20 g). Et eksempel på et leje efter og et vibrationssignal i løbet af et eksperiment kan ses på Figur 6.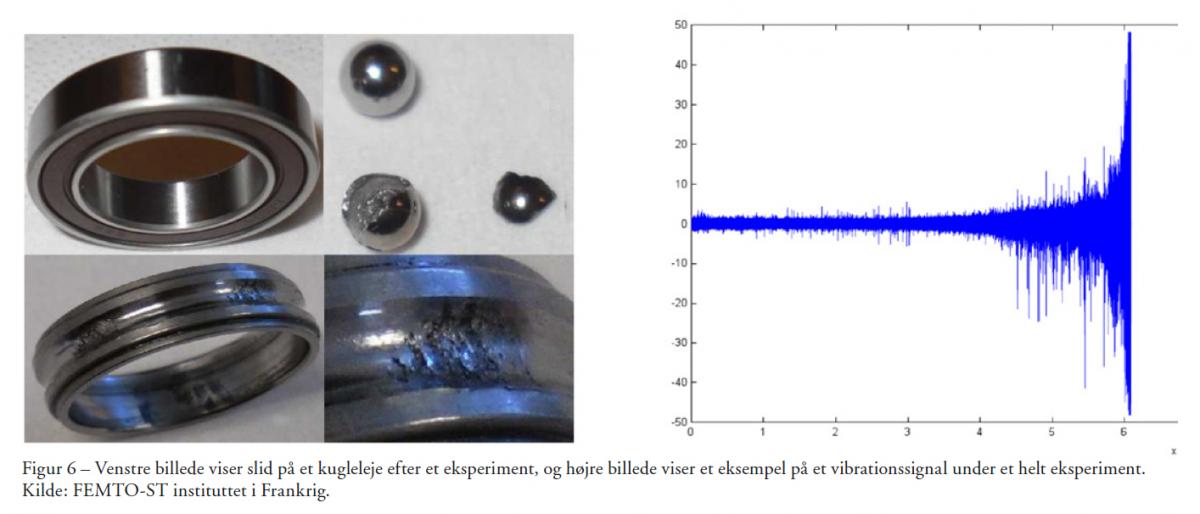
I vores tilfælde bruger vi RTF-data fra 15 af lejerne som træningsdata, og udtager RTF data fra to lejer til at teste metoderne. Vi udtrækker information fra de rå vibrationssignaler vha. nogle vibrationsanalyseværktøjer, og anvender metoderne på disse udtrukne data.
Potentialet på et virkeligt datasæt
Også på dette datasæt klarer LSTM sig bedre end CVA-metoden. RUL-grafer for LSTM kan ses på Figur 7.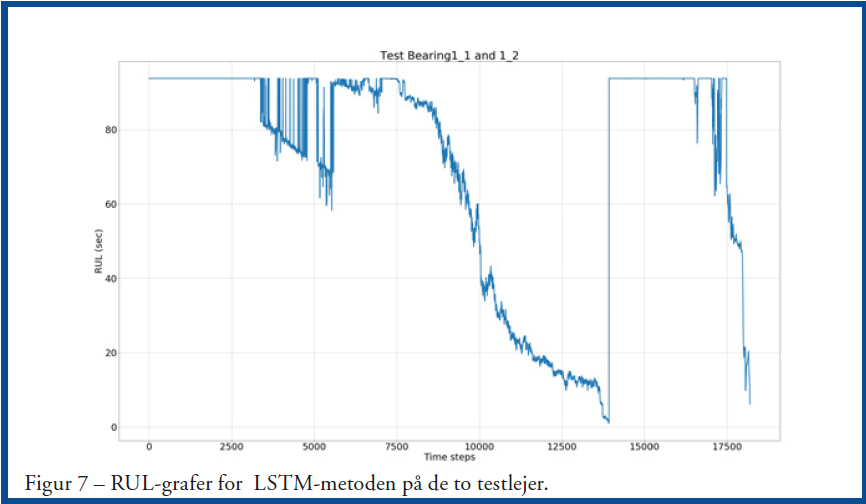
Bemærk, at de første 13.928 punkter svarer til det første testleje, mens de efterfølgende 4.268 svarer til det andet testleje. Figur 8.1 og 8.2 viser tilsvarende RUL-grafer ved CVA-metoden, og her kan det ses, at der er udfordringer for denne metode. Der er meget støj, men dog ender begge grafer med at ende tæt på RUL=0, som de jo skal, da det er RTF-data. LSTM RUL-graferne er dog med mindre støj og udvikler sig mere ensartet mod nedbrud.
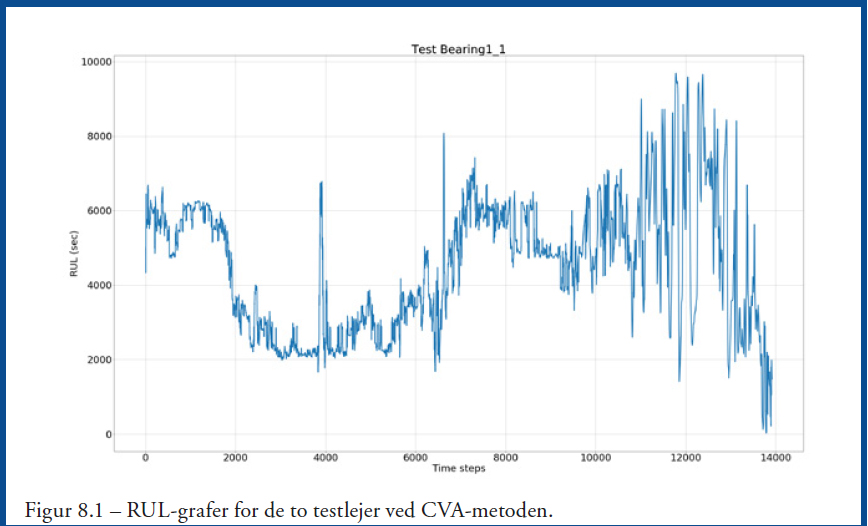
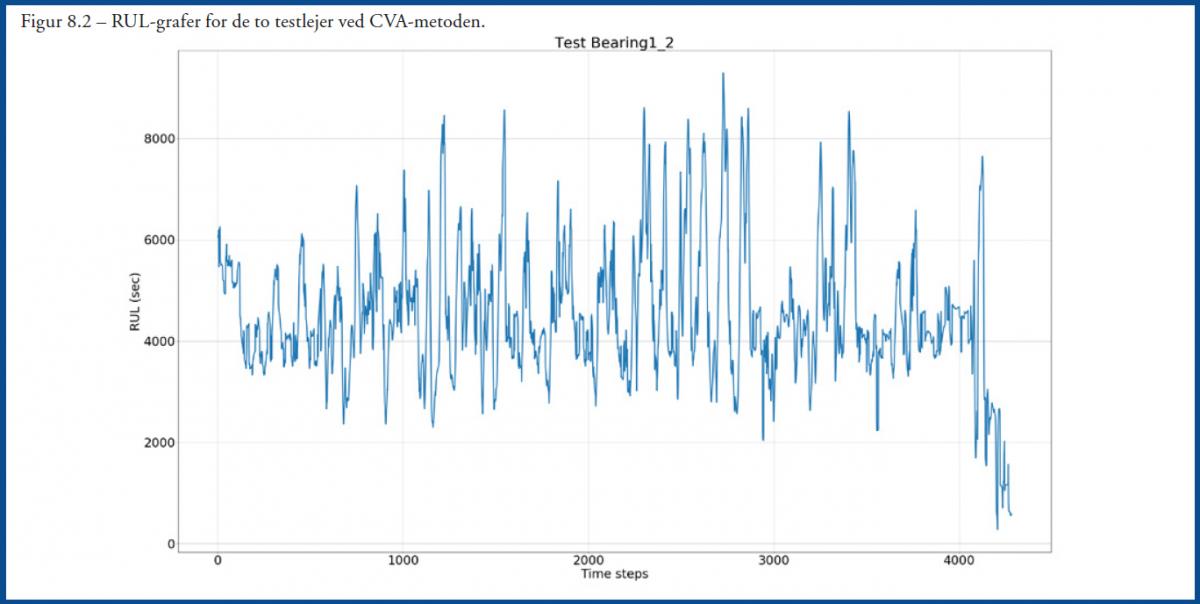
Perspektiverne
Der er de senere år sket en stigning i markedsstørrelsen inden for prædiktivt vedligehold og udviklingen forventes at fortsætte de kommende år. Dette skyldes bl.a. mere forskning samt billigere og hurtigere regnekraft. Den Danske Vedligeholdsforening estimerer, at den årlige omkostning ved nedbrud og produktionsstop i danske virksomheder som følge af dårligt vedligehold er ca. 25 mia. DKK. Anodot.com skriver, at virksomheder globalt vil spare $240 til $630 mia. i år 2025 grundet implementering af prædiktivt vedligehold. Det sker ved, at vedligeholdsomkostningerne reduceres med 10-40 %, samt nedetiden på udstyr reduceres med 50 %. Desuden reduceres kapitalinvesteringen med 3-5 % grundet længere levetid på maskiner og udstyr. Perspektiverne i prædiktivt vedligehold er således lovende, idet værktøjet søger at optimere vedligeholdsstrategien og dermed kunne spare nogle af disse milliarder. Og metoderne i denne artikel på de to datasæt viser netop, at det er muligt at få forholdsvist præcise mål for, hvornår der kræves vedligehold.
For at nævne en virksomhed anvender Ørsted A/S nu prædiktivt vedligehold på havvindmøller - ifølge Ingeniøren. Potentialet er her, at metoden reducerer de dyre sejlture ved at skelne de fejl, der skal rettes hurtigt fra dem, der godt kan vente. Man vedligeholder altså ud fra data og ikke efter planlagte intervaller. Man bruger her sammen med data teknikernes feedback, når algoritmen forudsiger, at det er tid til at skifte en komponent. Herved bliver algoritmen med tiden bedre og bedre til at komme med korrekte forudsigelser. Her er de altså gået skridtet videre og bestemmer samtidigt med restlevetiden også diagnosen. Også CeramicSpeed tilbyder nu overvågning af keramiske kuglelejer for at kunne sætte meget præcist ind med vedligehold.
Prædiktivt vedligehold er altså en tilgang, der lover positivt i forhold til at kunne spare virksomheder for unødvendige udgifter ved at optimere vedligeholdelsesstrategien, og tilgangen er set anvendt i flere virksomheder.