Fortatter:
Jesper Pedersen
Siemens Gamesa
Renewable Energy A/S
Maskinen er brudt sammen - hvad bruger vi nedetiden på?
Vi kommer ikke uden om utilgængelighed pga. havarier. Dette kaldes også uplanlagte stop, afhjælpende vedligehold eller ganske enkelt reparationer. For, som vi kender det fra pålidelighedsteorien og RCM, så fejler maskiner ofte ganske tilfældigt, uafhængigt af driftstid og alder. Med andre ord; vi kan ikke planlægge alt vedligehold, da maskinernes tendens til at fejle vilkårligt ikke tillader en sådan planlægning.
Så kan vi passende spørge os selv; Hvor gode er vi til at kunne udbedre fejl hurtigt, så vi kan få maskinerne i drift igen? Og hvad sker der rent faktisk i den tid vi er nede?
Lad os starte med at ridse et typisk eksempel op på forskellige faser i nedetiden:
1. Maskinen standser og fejlen registreres
2. Reaktionstid og kommunikation af problemet til vedligeholdsteamet. (Intern administrativ forsinkelse)
3. Ventetid på ressourcer (logistisk forsinkelse)
4. Fejlfinding
5. Ventetid på reservedele (logistisk forsinkelse)
6. Reparationstid
7. Funktionskontrol (testkørsel)
8. Maskinen leveres tilbage til driften
I dette er ikke indeholdt hviletid, hvilket kan være aktuelt for større reparationer. Desuden kan der være andre og simple reparationer, hvor antallet af punkter ikke vil være så stort. Ovenstående punkter kan man også stille op grafisk, så det bliver lidt nemmere at se sammenhængen mellem de forskellige tider.
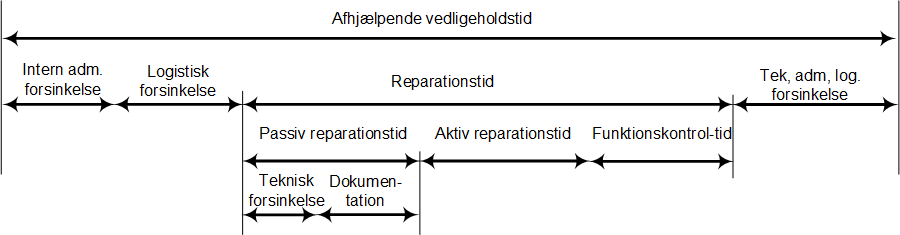
1 Vedligeholdstider
Nedetiden er summen af de 8 punkter ovenfor - eller den lange bjælke foroven kaldet ’Afhjælpende vedligeholdstid’. I den grafiske afbildning ses det tydeligt at ’Aktiv reparationstid’ kun er et element af en lang række forskellige aktiviteter. Den kan virke ganske lille her, men for nogle typer jobs vil den naturligvis være noget større.
Man kunne argumentere for at alt der ikke hedder ’Aktiv reparationstid’ dermed er lig med passiv tid. Ikke forstået på den måde at organisationen sidder passivt og ser til mens uret tikker, men passiv set ud fra maskinens/linjens tilgængelighed.
Ovenstående figur kræver muligvis et par forklaringer, så de kommer her:
Teknisk forsinkelse. Relaterer til situationer ifm. at gøre arbejdsstedet sikkert. Afkøling, ventilering, positionering af maskinen osv., så der er adgang til det fejlramte system. Eksempelvis handler det om at isolere systemet for potentiel energi såsom tryk eller spænding.
Aktiv reparationstid. Populært sagt er det her hvor multimeteret eller skruetrækkeren er i hånden.
Funktionskontrol. Omhandler aktiviteten med at verificere, om den reparerede enhed nu er i stand til at køre videre, dvs. om fejlen rent faktisk er blevet afhjulpet.
Når maskinerne uundgåeligt fejler, er det vigtigt, at vi er beredte, hvilket vi kender fra EN13306 som Vedligeholdssupport. Det handler basalt set om, at de nødvendige ressourcer er tilgængelige for at kunne udføre reparationen. Ressourcer skal her forstås som eksempelvis personale, reservedele, dokumentation og værktøj.
Hvis vi kobler vedligeholdssupport og nedetid, kan man ret hurtigt lave følgende afledning: Evnen til at levere en god vedligeholdssupport afspejles i nedetidens varighed. Men det er jo heller ikke helt sandt, da nedetiden består af en række forskellige elementer. Somme tider hører man begrebet Mean Waiting Time (MWT) som et udtryk for den gennemsnitlige ventetid. I denne kontekst vil ventetiden mere eller mindre præcist afspejle hvor effektiv man er til disciplinen vedligeholdssupport.
Så kommer spørgsmålet; Har I detaljerede data på tidsforbruget på jeres arbejdsordrer? Dvs. en breakdown af arbejdsordren i passende tidsblokke/ -kategorier. Mange vil sikkert svare nej, da nedetiden for nemheds skyld ofte bliver sat lig med reparationstiden. Hvis man så lægger en række jobs sammen og deler med antallet, vil man få et tal der hedder Middeltid til genopretning (MTTR). Dette mål inkluderer det hele ovenfor, dvs. både den aktive og passive del. Sådan en detaljeringsgrad kan være fornuftig nok, men hvis man ønsker at dykke dybere ned og dissekere nedetiden, er en differentiering i forhold til rapportering nødvendig. Hvordan får man så bedre indsigt i hvad tiden er brugt på - uden at registrere sig selv ihjel?
Ja, der findes nok ikke et simpelt og universelt svar på netop det. Men først og fremmest vil jeg nok anbefale at definere ens ambitionsniveau. Hvis man ikke har styr på de basale ting og får registreret særligt meget, er det måske for tidligt at begynde på det her. Eksempelvis vil det nok ikke give mening at dissekere nedetiden, hvis man ikke får registreret hvilken type vedligehold man udfører og hvor lang tid det tog. Dernæst bør man starte simpelt og sørge for, at man senere kan udbygge ens registrering efter behov - og efterhånden som ens IT-systemer bliver bedre og mere integreret.
Som I måske har fundet ud af, er jeg glad for standarder, hvilket jeg også skrev om i dette indlæg. Derfor har
jeg da også et par forslag til det videre arbejde:
DS/EN 15341 Vedligehold - KPI’er for vedligehold kan hjælpe med til at definere passende (K)PI’er. Den er delt op i økonomiske, tekniske samt organisatoriske måltal. En del af disse måltal berører også nedetid.
DS/EN13306:2017 Terminologi for vedligehold Annex D i denne standard indeholder god inspiration til opdelingen af tider, hvilket jeg også har brugt til at lave ovenstående figur.
Hvis man har et specifikt ønske om at forbedre sit vedligeholdsteams evner til at fejlfinde, vil det naturligvis være fordelagtigt at kunne separere tiden brugt på fejlfinding ud fra reparationstiden. Dog skal man omhyggeligt vælge hvilke handlinger man registrerer, så det ikke bliver en byrde og (mere) bureaukrati. Jeg vil naturligvis aldrig anbefale, at gå amok med at registrere alt i detaljer og lave micro-management, da det ganske sikkert vil have den modsatte effekt og resultere i mere passiv tid samt misfornøjede teknikere.
| Filer | ||
| Filnavn | Størrelse | Sidst ændret |
|---|---|---|
| 254.31 KB | 08/05 2019 | |